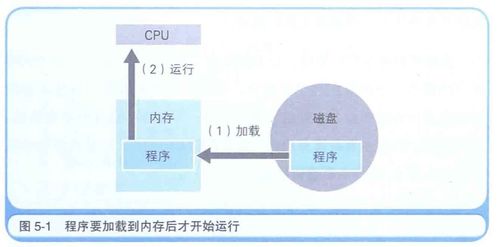
隨著AI應用從離線批量訓練向實時化、在線化演進,對數據處理系統的實時性、一致性和可擴展性提出了更高要求。Apache Flink作為一款高性能的流處理引擎,憑借其低延遲、高吞吐、精確一次(exactly-once)語義和強大的狀態管理能力,已成為支撐AI在線場景(如特征工程、在線學習、在線預測)的核心基礎設施。本文將系統闡述Flink如何為這些AI場景提供數據處理與存儲支持。
一、特征工程的實時化支持
特征工程是AI流程中耗時最長的環節之一,傳統批處理模式無法滿足實時推薦、風控等場景對特征新鮮度的要求。Flink通過以下方式實現特征工程的實時化:
- 實時特征抽取與計算:Flink DataStream API允許用戶從Kafka、Pulsar等消息隊列中實時消費原始數據(如用戶點擊流、交易記錄),通過自定義算子或內置函數(如滾動/滑動窗口聚合、CEP復雜事件處理)實時生成統計類、序列類特征。例如,實時計算用戶最近1小時的點擊次數、購買轉化率等。
- 特征歸一化與編碼的流式更新:對于需要全局統計信息的特征(如歸一化的均值方差、分箱閾值),Flink可利用其狀態后端(如RocksDB)維護全局狀態,并基于流數據增量更新統計量,確保特征編碼的實時性。
- 特征存儲與同步:計算后的特征可實時寫入在線特征庫(如Redis、Cassandra、HBase),供下游在線預測服務低延遲查詢。Flink的Connector生態支持與多種存儲系統高效集成,且通過冪等寫入保證特征一致性。
二、在線學習的流式訓練支持
在線學習使模型能夠根據實時數據持續更新,適應數據分布的變化。Flink為在線學習提供了端到端的流水線:
- 流式樣本生成:Flink可將實時事件(如曝光、點擊)與上下文特征結合,動態構造帶標簽的訓練樣本流,支持負采樣、樣本加權等操作。
- 增量模型訓練:通過與機器學習庫(如Alink、Flink ML)集成,Flink支持在數據流上執行在線學習算法(如FTRL、在線梯度下降)。Flink的檢查點機制可定期保存模型狀態,保證訓練容錯;其時間窗口機制可用于控制模型更新頻率。
- 模型評估與發布:訓練過程中可實時計算模型性能指標(如AUC、準確率),并通過側輸出流將滿足條件的模型版本發布到模型倉庫(如S3、HDFS),或直接熱更新到在線預測服務。
三、在線預測的低延遲服務支持
在線預測要求毫秒級響應,且需與特征工程、模型更新流程無縫銜接。Flink的助力體現在:
- 實時特征拼接:對于需要復雜特征拼接的預測請求,Flink可利用Async I/O功能并發查詢多個特征庫,在毫秒內完成特征拉取與拼接,避免預測服務直接耦合多數據源。
- 流式預測與反饋收集:Flink可將預測請求流與模型服務(如TensorFlow Serving、PyTorch Serve)集成,實現批量預測與結果流式輸出。預測結果與后續的用戶反饋行為可重新匯入數據流,形成“預測-反饋”閉環,用于模型評估與迭代。
- A/B測試與流量分配:通過Flink的流處理能力,可實時對預測請求進行分桶,將不同流量導向不同模型版本,并實時聚合各版本的業務指標,支撐在線實驗與決策。
四、數據處理與存儲的架構支撐
Flink為上述AI場景提供了統一的底層支撐架構:
- 狀態管理:Flink內置的狀態后端(內存、RocksDB)可高效存儲特征統計值、模型參數等中間狀態,并通過檢查點持久化,保證故障恢復后狀態一致性。
- 數據一致性與時效性:基于事件時間處理與水位線機制,Flink能處理亂序數據,確保特征計算的時間語義準確;其精確一次語義保證數據不重不漏。
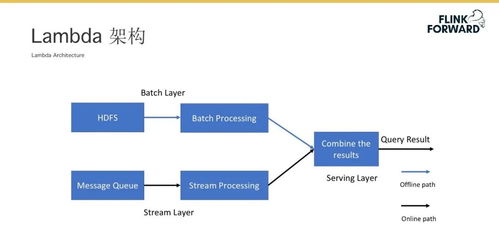
- 存儲集成與數據流轉:通過豐富的Connector,Flink可實現與離線數倉(Hive)、消息隊列(Kafka)、在線數據庫(Redis)等的雙向數據同步,打通離線與在線數據孤島,構建統一的特征存儲與模型服務管道。
- 資源彈性與運維:在Kubernetes等云原生環境下,Flink可自動擴縮容,應對流量峰值;其監控指標(如延遲、吞吐)與告警集成便于運維。
Flink以其強大的流處理核心能力,為AI在線場景提供了從實時特征計算、流式模型訓練到低延遲預測的全鏈路支持。通過將數據處理邏輯與AI流程深度整合,Flink助力企業構建響應敏捷、持續演進的智能實時系統,驅動AI應用從“離線感知”邁向“在線智能”。